
ElevenLabs hoạt động như thế nào? Giải thích dễ hiểu cho người mới 2026

ElevenLabs hoạt động như thế nào là câu hỏi được rất nhiều người mới quan tâm khi bắt đầu làm voice AI, video ngắn, podcast và nội dung số trong năm 2026. Không chỉ nổi bật với khả năng tạo giọng nói tự nhiên, ElevenLabs còn giúp người dùng tiết kiệm thời gian sản xuất nội dung và nâng cao chất lượng âm thanh đầu ra. Trong bài viết này, Techlogin sẽ chia sẻ cho bạn cách ElevenLabs vận hành, những tính năng nổi bật và lý do vì sao công cụ này đang được nhiều nhà sáng tạo lựa chọn.
ElevenLabs hoạt động như thế nào? Giải thích dễ hiểu từng bước
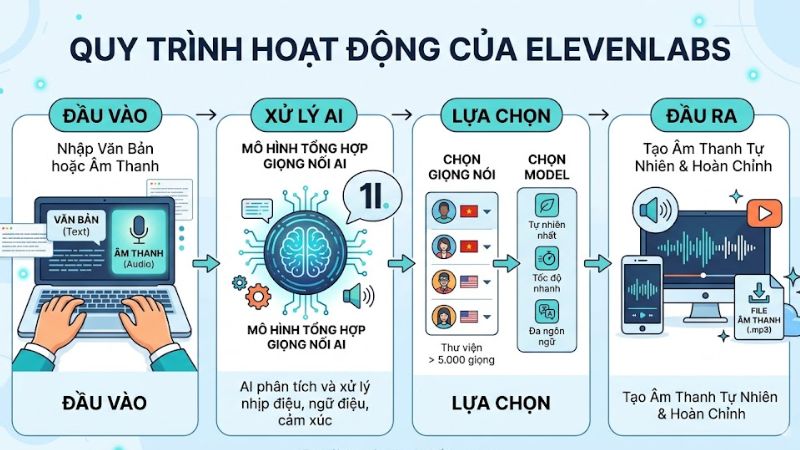
ElevenLabs là một nền tảng AI audio nhận văn bản hoặc âm thanh đầu vào, sau đó dùng mô hình tổng hợp giọng nói để tạo ra âm thanh mới nghe tự nhiên hơn kiểu TTS truyền thống. Nói đơn giản, bạn chọn một “giọng”, chọn một “model” phù hợp với mục tiêu của mình, nhập nội dung, rồi hệ thống sẽ xử lý nhịp điệu, ngữ điệu, cảm xúc và tạo file âm thanh hoàn chỉnh. Theo tài liệu chính thức, ElevenLabs hiện có thư viện hơn 5.000 giọng nói, trong khi các model khác nhau sẽ quyết định độ tự nhiên, tốc độ xử lý và số ngôn ngữ hỗ trợ.
Bạn đưa nội dung đầu vào cho hệ thống
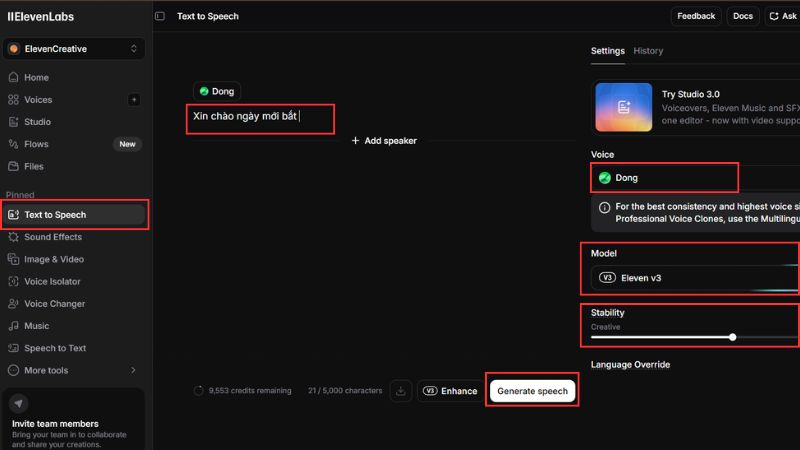
Bước đầu tiên rất đơn giản: bạn nhập nội dung vào. Với tính năng Text to Speech, người dùng chỉ cần vào trang tạo giọng, gõ hoặc dán văn bản, sau đó chọn giọng và nhấn Generate để tạo file audio. Đây là quy trình cơ bản nhất mà người mới có thể bắt đầu ngay.
Nếu không phải văn bản, bạn cũng có thể đưa vào audio hoặc video ở một số tính năng khác. Ví dụ, với dubbing, ElevenLabs nhận file âm thanh hoặc video rồi tách lời nói của từng người, dịch sang ngôn ngữ khác và tái tạo lại phần tiếng nói mà vẫn cố giữ nhịp, cảm xúc và chất giọng gốc. Với speech to text, hệ thống làm ngược lại: nhận giọng nói rồi chuyển thành văn bản.
Hệ thống phân tích nội dung bạn nhập
Sau khi nhận văn bản, ElevenLabs không chỉ “đọc từng chữ một”. Các model của họ sẽ phân tích dấu câu, cấu trúc câu, nhịp nói và tín hiệu ngữ cảnh để quyết định nên đọc nhanh hay chậm, nhấn ở đâu, nghỉ ở đâu và thể hiện cảm xúc như thế nào.
Đây là lý do vì sao giọng tạo ra thường nghe tự nhiên hơn các công cụ TTS đời cũ. Tài liệu model của ElevenLabs cũng nhấn mạnh rằng model Eleven v3 được thiết kế để tạo giọng nói giàu cảm xúc và hiểu ngữ cảnh tốt hơn trên nhiều ngôn ngữ.
Bạn chọn “giọng nói” phù hợp
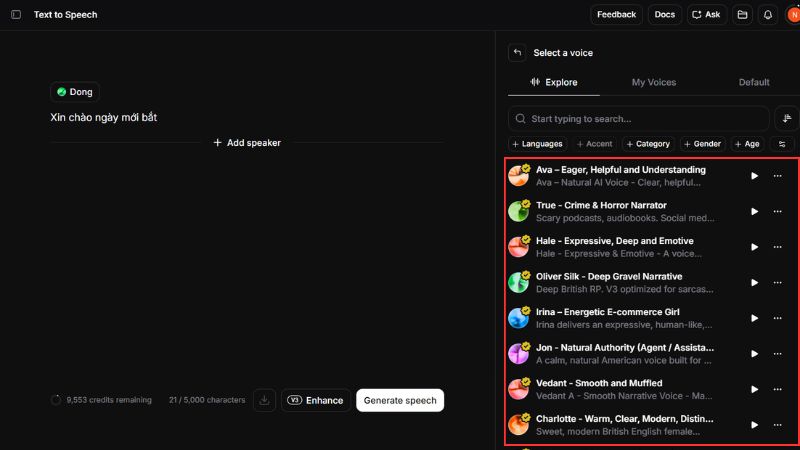
Giọng nói trong ElevenLabs giống như “nhân vật” sẽ cất tiếng nói. Theo tài liệu chính thức, yếu tố ảnh hưởng lớn nhất đến chất lượng đầu ra là voice selection, sau đó mới đến model selection, rồi mới đến các thiết lập phụ. Nói cách khác, chọn đúng giọng đọc gần với mục tiêu nội dung thường quan trọng hơn việc chỉnh quá nhiều thông số.
ElevenLabs có nhiều loại giọng khác nhau: giọng mặc định, giọng trong thư viện, giọng do AI thiết kế và giọng do người dùng clone. Nếu bạn tạo nội dung tiếng Việt, cách an toàn nhất là chọn giọng gốc phù hợp với tiếng Việt hoặc clone từ một giọng nói tiếng Việt rõ ràng.
Bạn chọn model để cân bằng chất lượng và tốc độ
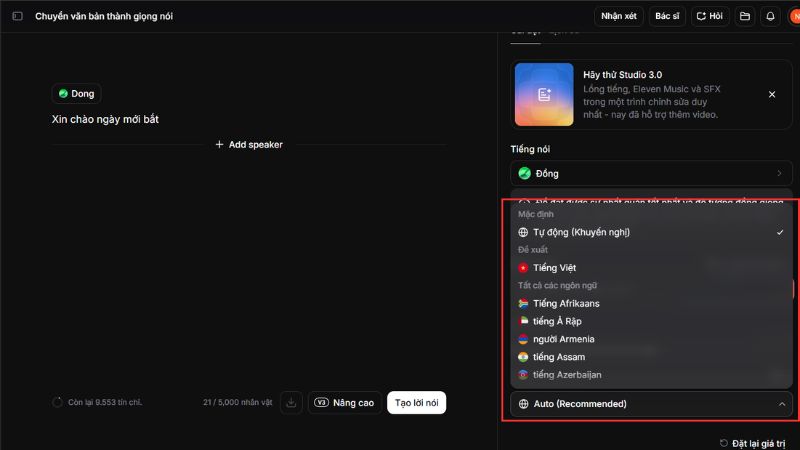
Một điểm rất quan trọng khi giải thích ElevenLabs hoạt động như thế nào là phải hiểu vai trò của model. ElevenLabs hiện có nhiều model khác nhau cho từng nhu cầu. Trong nhóm text to speech, Eleven v3 là model giàu cảm xúc và biểu cảm nhất, hỗ trợ hơn 70 ngôn ngữ; trong khi Flash v2.5 là model tốc độ cao, độ trễ khoảng 75ms, phù hợp cho tác vụ thời gian thực.
Điều này có nghĩa là nếu bạn làm video review, kể chuyện, đọc quảng cáo hay cần cảm xúc rõ ràng, model chất lượng cao sẽ phù hợp hơn. Nếu bạn làm trợ lý thoại, AI call hoặc ứng dụng cần phản hồi gần như ngay lập tức, Flash sẽ hợp lý hơn.
Hệ thống tổng hợp âm thanh và trả file hoàn chỉnh
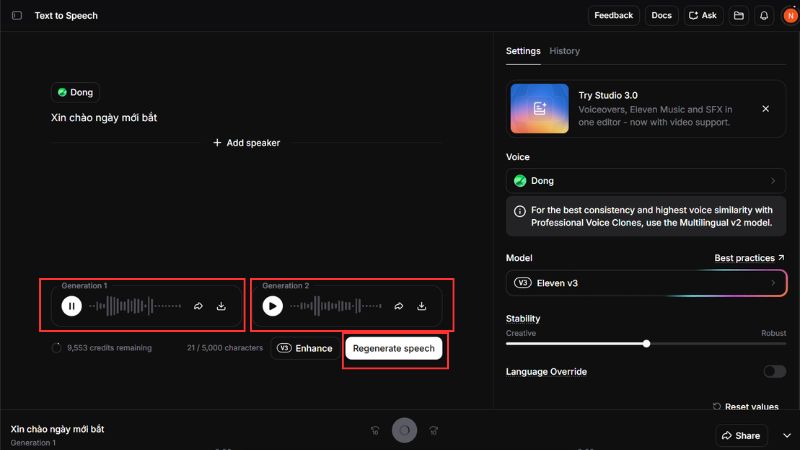
Sau khi đã có văn bản, giọng và model, ElevenLabs sẽ tổng hợp thành file âm thanh. Người dùng chỉ cần nhấn Generate là hệ thống xử lý và xuất ra audio để nghe, tải về hoặc dùng tiếp trong sản phẩm khác.
Voice Cloning trong ElevenLabs là gì?
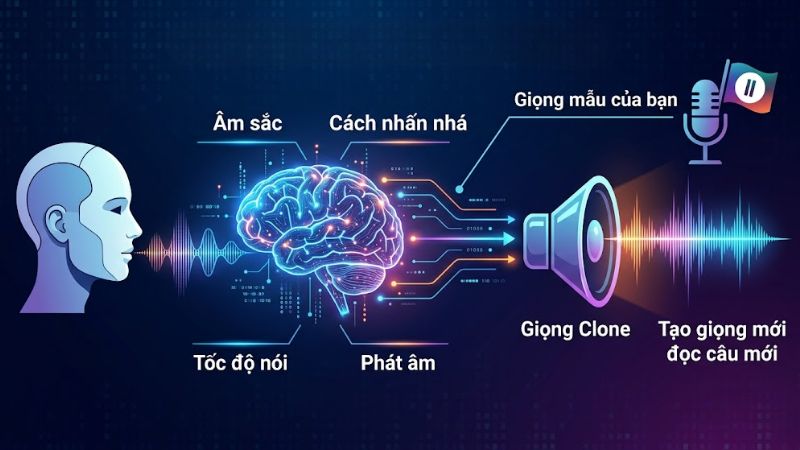
Khi tìm hiểu ElevenLabs hoạt động như thế nào, nhiều người thường quan tâm nhất đến tính năng clone giọng. Hiểu đơn giản, ElevenLabs sẽ nghe và phân tích giọng mẫu của bạn, sau đó học các đặc điểm như âm sắc, cách nhấn nhá, tốc độ nói và cách phát âm. Hệ thống có thể tạo ra một giọng mới nghe gần giống giọng gốc, kể cả khi đọc những câu hoàn toàn mới.
Ưu và nhược điểm của ElevenLabs cho người mới
Để hiểu rõ hơn ElevenLabs hoạt động như thế nào, bạn cũng nên nhìn qua những điểm mạnh và điểm hạn chế của nền tảng này.
Ưu điểm của ElevenLabs
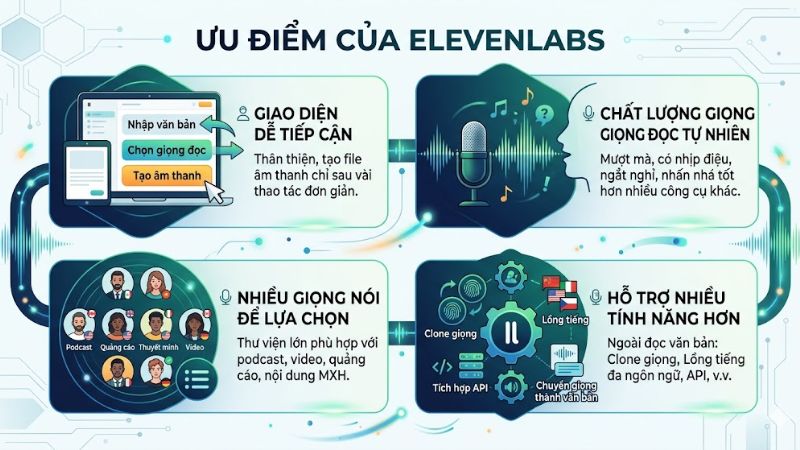
Giao diện dễ tiếp cận: ElevenLabs có giao diện khá thân thiện, có thể nhập văn bản, chọn giọng đọc và tạo file âm thanh chỉ sau vài thao tác đơn giản.
Chất lượng giọng đọc tự nhiên: Giọng đọc được tạo ra thường mượt hơn, có nhịp điệu, biết ngắt nghỉ và nhấn nhá tốt hơn so với nhiều công cụ đọc văn bản truyền thống.
Nhiều giọng nói để lựa chọn: ElevenLabs có thư viện giọng nói khá lớn, phù hợp với nhiều mục đích khác nhau như làm video, podcast, thuyết minh, quảng cáo hay nội dung mạng xã hội.
Hỗ trợ nhiều tính năng hơn chỉ là đọc văn bản: Ngoài tạo giọng đọc từ văn bản, ElevenLabs còn có các tính năng như clone giọng, lồng tiếng đa ngôn ngữ, chuyển giọng nói thành văn bản và tích hợp API.
Nhược điểm của ElevenLabs
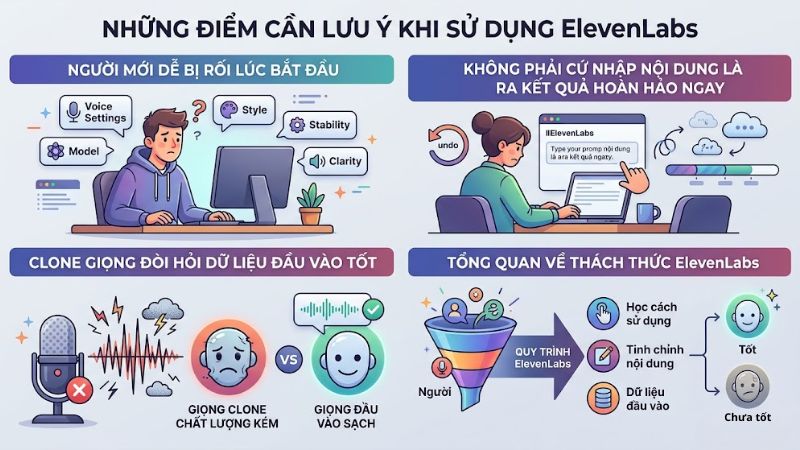
Người mới dễ bị rối lúc bắt đầu: Khi mới dùng, nhiều người sẽ thấy hơi choáng vì ElevenLabs có khá nhiều lựa chọn như voice, model, style và các thiết lập khác nhau.
Không phải cứ nhập nội dung là ra kết quả hoàn hảo ngay: Muốn giọng đọc hay, bạn vẫn cần thử nhiều lần, chỉnh lại câu chữ, dấu câu và chọn giọng phù hợp.
Clone giọng đòi hỏi dữ liệu đầu vào tốt: Nếu bạn muốn clone giọng đẹp, file ghi âm phải sạch, ít tạp âm và giọng nói rõ ràng, nếu audio bị rè, có nhiều tiếng ồn hoặc có nhiều người cùng nói, chất lượng giọng clone sẽ giảm đi đáng kể.
Kết Luận:
ElevenLabs hoạt động như thế nào? Hiểu đơn giản, đây là nền tảng AI audio Chỉ cần chọn đúng giọng đọc, đúng model, viết nội dung theo cách nói tự nhiên và thử tinh chỉnh vài lần, bạn đã có thể tạo ra voice AI chất lượng cao cho nhiều mục đích khác nhau. Nếu bạn đang muốn sử dụng ElevenLabs ổn định và tiết kiệm hơn, hiện tại Techlogin đang cung cấp các gói bản quyền ElevenLabs giá rẻ, hỗ trợ nhanh để có trải nghiệm sớm nhất.




